AI agents have moved past answering questions. They do things now: query and update databases, send email, move money, deploy code, and click through web apps for a user. Some can run a computer on their own with nobody watching. Visa and Mastercard both shipped agent payment tools in 2025, so "an agent moves money" is already real, not a thought experiment.
That is useful, and it is where the problem starts. When an agent takes an action today, almost nothing checks whether it was allowed to. The agent has the credentials and the tools, so it runs. If the request was a user's mistake, or was planted by a malicious web page, email, or document through prompt injection, the action goes through anyway.
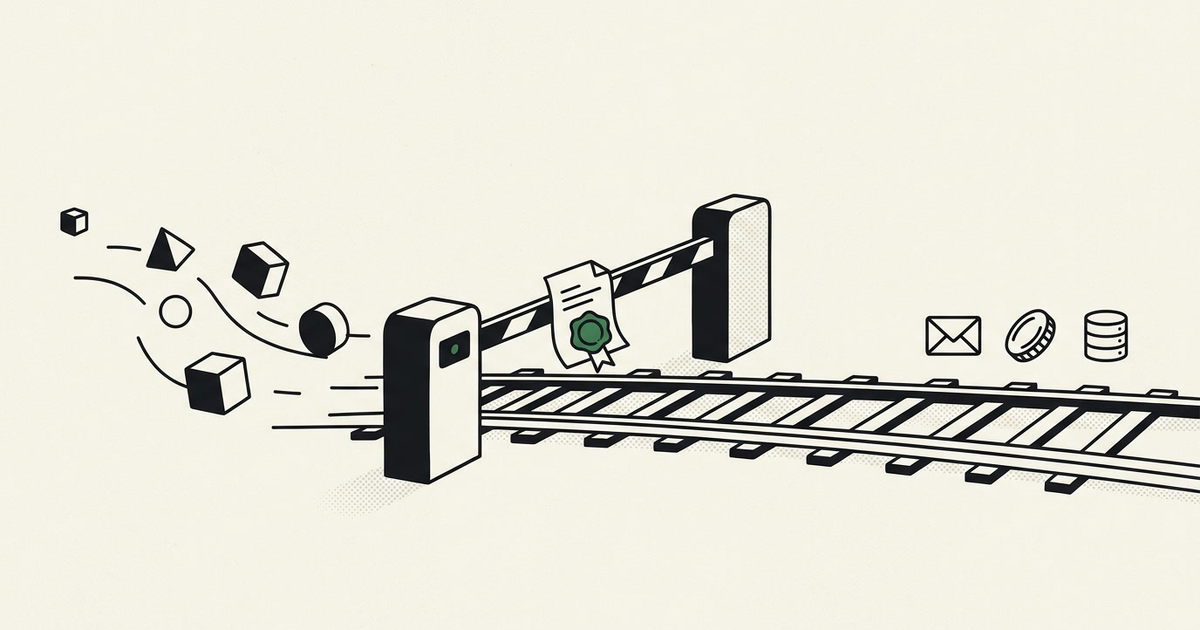
PermitRail is an open-source permission and audit layer for exactly this. It sits between an agent and the tools it can call. Before a sensitive action runs, it checks a policy you define, stops and asks for approval of that specific action, and records a signed proof of what was approved and what actually ran. If you have built anything that handles payments or personal data, you know the pattern already: an approval step for risky operations, and an audit trail you can trust.
The problem, in plain terms
Until recently, a model produced output and a person decided what to do with it. It could write broken code or give bad advice, but a human still sat between that output and any real consequence. You reviewed the code before you shipped it. You read the answer before you acted on it. That review step was the safety check, even if no one called it that.
Agents remove that step. The model no longer suggests an action, it takes it. When an agent drops a database table or sends a payment, nobody reads it first. The mistake and the consequence happen in the same move.
So the questions worth asking changed. They are the same ones banks, hospitals, and payment systems have asked about their own software for decades: Was this exact action allowed? Who approved it? Can you prove it afterward? For most agent setups today, the honest answer to all three is no.
And the failure modes are not theoretical. Prompt injection, where hidden text in a page or file hijacks an agent's instructions, is one of the most reported weaknesses in agent systems. Coding agents with direct database access have already deleted production data. As people hand agents stored payment cards, live inboxes, and cloud access, one wrong move does a lot more damage.
How PermitRail handles it
PermitRail puts a checkpoint in front of the agent's actions. You start with a policy: which tools run freely, which are blocked, and which need sign-off. Anything you have not listed is denied by default.
When an agent reaches for a tool that needs sign-off, PermitRail stops it and asks for approval. The approver, a person or another trusted service, sees the real details: the actual recipient, the exact amount, and the reason the agent gave. They approve that one action, not a blanket yes.
Once approved, PermitRail issues a short-lived proof tied to that exact action. The tool runs once. A receipt goes into the audit log. Replay the same proof and it is rejected.
In code, the flow is small:
const action = {
tool: 'send_payment',
audience: 'billing-agent',
subject: 'user_123',
purpose: 'Pay invoice INV-42',
input: { to: 'alice', amount: 500 },
};
const decision = await gateway.authorize(action);
if (decision.outcome === 'require_proof' && decision.challenge) {
const proof = await provider.approve(decision.challenge.id); // your approval channel
await gateway.execute(action, sendPayment, { proofEnvelope: proof });
}The proofs and receipts are signed with Ed25519. That is the part that matters: you do not have to trust PermitRail, my code, or any server. You verify a proof or receipt yourself, later, offline, in any language. Change the amount or the recipient after approval and the proof stops matching. Fake a receipt for an action that never ran and it fails to verify. The audit log is evidence, not a log you are asked to believe.
Using it
PermitRail is on npm as a small set of TypeScript packages with no runtime dependencies. You install the core, a gateway, and an approval provider, then wire it in front of your tool calls. The same code runs in Node, the browser, and on edge runtimes.
It also ships a ready-to-run MCP server. If you build agents with Claude, Cursor, or any MCP client, you route sensitive tool calls through PermitRail without writing the permission layer yourself.
Why it is open source
Almost every team building agents hits this, and most either skip it or rebuild a private version inside their own product. That is wasted work, and a permission layer is not something you want to improvise under a deadline. Shared, inspectable infrastructure is the sensible answer, for the same reason we use established cryptography libraries instead of writing our own.
There is a bigger reason too. As agents get more authority over money, accounts, and infrastructure, the controls around that authority become a safety and governance question, not only an engineering one. We do not give people that kind of access without approvals and a record. Agents should not be the exception. That is the part of this field I want to keep working on.
What PermitRail does not do
It is not a magic safety wrapper. It does not make an unsafe tool safe on its own. It is a gate, a proof, and an audit trail. You still validate inputs, protect secrets, and keep your own authorization in place. It also defaults to a single process today, so running it across many instances means plugging in a shared store. The interfaces for that are already there.
Try it
If you are building agents that can touch real users, money, data, or production, take a look.
- Live sandbox: https://chokonaira.github.io/permitrail/
- GitHub: https://github.com/chokonaira/permitrail
- npm: https://www.npmjs.com/org/permitrail
- Threat model: https://github.com/chokonaira/permitrail/blob/main/docs/threat-model.md
If you try it and something is confusing or broken, tell me, or open an issue.